Learning to Estimate Robust 3d Human Mesh from in-the-wild Crowded Scenes
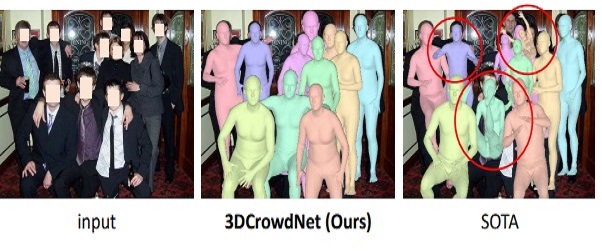
We consider the problem of recovering a single person’s 3D human mesh from in-the-wild crowded scenes. While much progress has been in 3D human mesh estimation, existing methods struggle when test input has crowded scenes. The first reason for the failure is a domain gap between training and testing data. A motion capture dataset, which provides accurate 3D labels for training, lacks crowd data and impedes a network from learning crowded scene-robust image features of a target person. The second reason is a feature processing that spatially averages the feature map of a localized bounding box containing multiple people. Averaging the whole feature map makes a target person’s feature indistinguishable from others. We present 3DCrowdNet that firstly explicitly targets in-the-wild crowded scenes and estimates a robust 3D human mesh by addressing the above issues. First, we leverage 2D human pose estimation that does not require a motion capture dataset with 3D labels for training and does not suffer from the domain gap. Second, we propose a joint-based regressor that distinguishes a target person’s feature from others. Our joint-based regressor preserves the spatial activation of a target by sampling features from the target’s joint locations and regresses human model parameters. As a result, 3DCrowdNet learns target-focused features and effectively excludes the irrelevant features of nearby persons. We conduct experiments on various benchmarks and prove the robustness of 3DCrowdNet to the in-the-wild crowded scenes both quantitatively and qualitatively. [paper]